



My colleagues Arman and Murtaza recently wrote an excellent blog about how artificial intelligence can be used with Quanser products. The section that introduces transfer learning really caught my attention. We’re living in an era of booming AI technology. There are over thousands of AI-related papers being published every year, and universities and industries work hard on creating robust machine learning algorithms for different purposes. Thanks to the open-source community, everyone can now access state-of-the-art machine learning models by simply downloading them from the Internet. With transfer learning, people can then retrain these downloaded models to adapt them to their own needs. So in this blog, I thought I share some open source links worthy of exploring, and show the result of using transfer learning on RetinaNet to develop a road sign detection model.
Where can I Find Those Treasures?
If you are ready to get your hands dirty with transfer learning, the first thing you want to have is a pre-trained model with the same overall functionality that you wish to achieve; for example, a model that does text classification or an object detection model that detects specific objects in an image. Let’s have a look at a few popular pre-trained models.
TensorFlow Hub
TensorFlow Hub is a great source for you to download pre-trained machine learning models. It also has tutorials to help you select an appropriate model to start off with. You can also publish your model to the hub and share it with others. RetinaNet is one of the models that you will find there.
The Tensorflow Hub website also introduces an API containing many functions like plotting and labelling, which can save you time during your development.
For example, check out the TensorFlow Object Detection API. I have used some of the tools like label_map_util, visualization_utils, and config_util to help me label my training images, visualize the images, and set up the model.
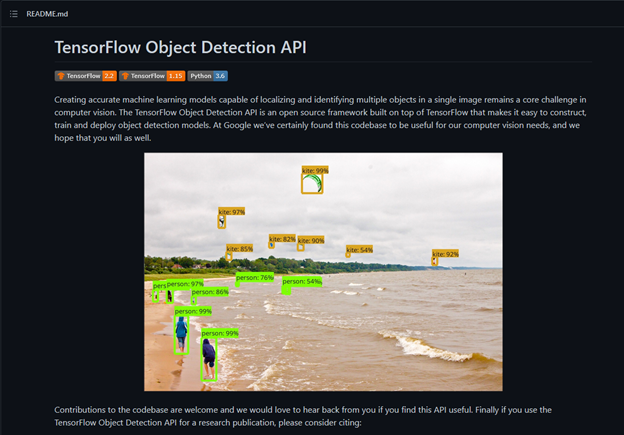
Keep in mind that machine learning models that involved computer vision usually consume a large amount of the graphical processing power on your computer. If your GPU isn’t powerful enough, it will take a longer time to train your model. Also, the dependencies or packages that you load will vary between different models. Thus, I recommend you use Google Colab, a cloud-based python editor that doesn’t require any configuration, provides free access to GPUs and TPUs, and is easy to share with others.
Transfer Learning on RetinaNet
My goal for this transfer learning task was to re-train an object detection model that would detect the Quanser QCar as well as the road signs pictured below.

After reading a few papers and trying several open-source software packages, I identified RetinaNet as the object detection model that I thought would best work for my intended application.
The RetinaNet network architecture is illustrated below. It consists of two subnets, one for classification and one for predicting the bounding boxes’ locations. Because of the beauty of transfer learning, I decided to keep everything inside the network architecture intact, except for the class subnets that I would retrain based on my training targets.
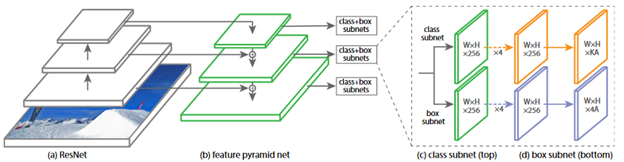

Regarding the transfer learning for RetinaNet, you only need to fine-tune the trainable variables in the class subnet and the box subnet. The custom training process is to pre-process the image, make the prediction, calculate the loss against the ground-truth bounding boxes, calculate the gradient regarding the total loss, and finally apply the gradients to the variables that need to be fine-tuned. The image below shows a snippet of the training code that I used. Keep in mind that used the model function inside Object Detection API, which is not a standard TensorFlow model, so that’s why model.predict and model.loss here also take the shape of the image as an input.
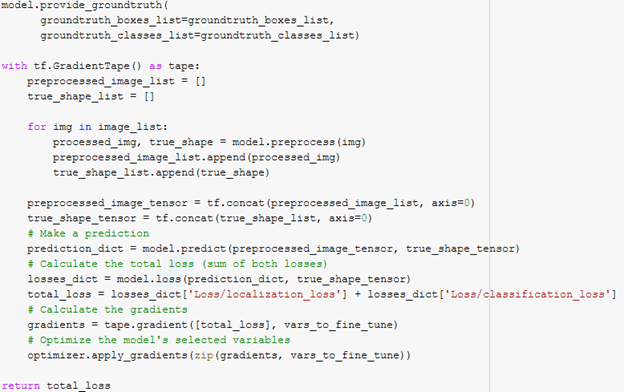
For the test dataset, I recorded a video from the RGBD camera on one of the QCars. I then placed signs in different locations, and let two QCars run on the track. Finally I converted the video to thousands of images and passed those into the predictor. The predictor function returned the detection boxes, detection classes, and the detection scores, which are the possibility.

The post-processed video below shows the results of my trained model. The model can detect the road signs as well as the QCars most of the time. Some possible improvements will be to take additional training images when the QCar is moving in the frame. Currently, all the training images were taken when the QCar was standing still. The motion blur, which shows in the video, wasn’t captured in the training dataset. Overall, I was satisfied with the results and now have a trained model to detect road signs and our QCar!
Some Final Words
When implementing an AI algorithm, there are many aspects that one could focus on. For example, the focus could be on parameter tuning or the design of the algorithm or the model at hand. In the interest of time, many users tend to look for an algorithm that can be quickly re-trained and deployed. This is where transfer learning proves to be one of the best approaches, given that there are so many state-of-the-art trained models in the open-source community. I’d love to hear how you use transfer learning in your applications. Let me know in the comments section below!


